|
Yun Qu | 曲云 I'm a fourth-year Ph.D. student in the Department of Automation at Tsinghua University, advised by Prof. Xiangyang Ji. My research focuses on Reinforcement Learning and Large Language Models. I work with the THU-IDM team, where we develop efficient algorithms for decision-making. Prior to my doctoral studies, I received my B.E. degree from the Department of Automation at Tsinghua University. |

|
News |
ResearchI'm interested in Reinforcement Learning and Large Language Models. My research focuses on efficient and intelligent decision-making with minimal environment interactions. |
|
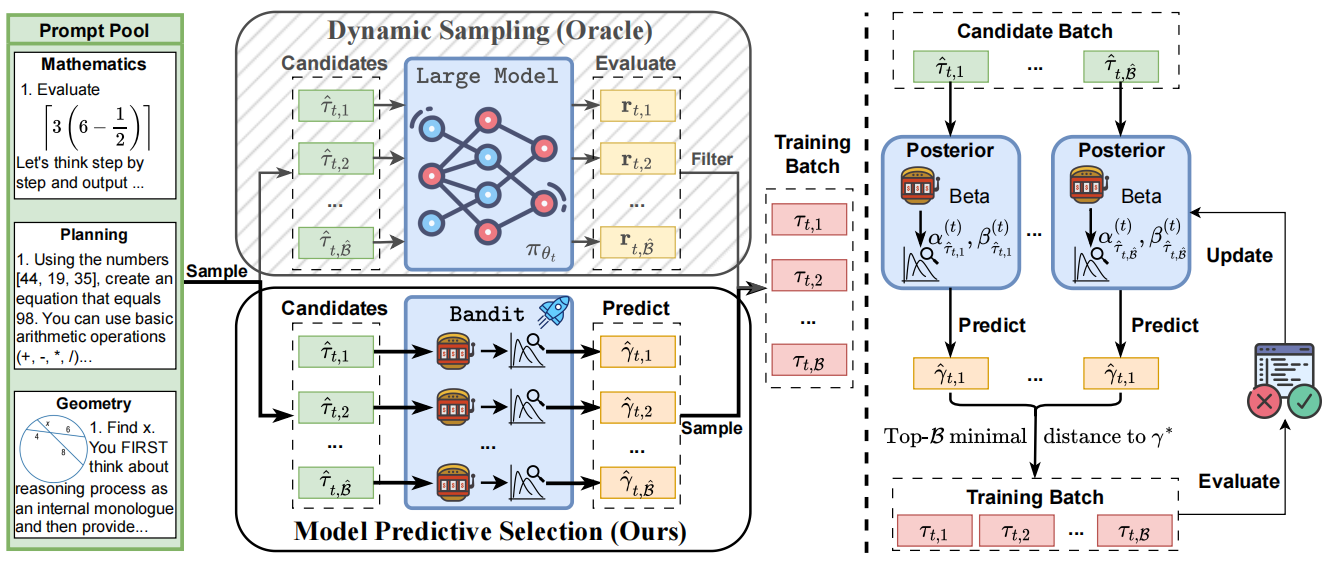
Can Prompt Difficulty be Online Predicted for Accelerating RL Finetuning of Reasoning Models?
Yun Qu, Qi (Cheems) Wang, Yixiu Mao, Vincent Tao Hu, Björn Ommer, Xiangyang Ji KDD, 2026 paper / code This work introduces Model Predictive Prompt Selection, a Bayesian risk-predictive framework that online estimates prompt difficulty without requiring costly LLM interactions. |
|
|
Adaptive Neighborhood-Constrained Q Learning for Offline Reinforcement Learning
Yixiu Mao, Yun Qu, Qi (Cheems) Wang*, Xiangyang Ji NeurIPS, 2025 Spotlight paper / code This work aims to address the over-conservatism of the density and sample constraints while avoiding complex behavior modeling required by the support constraint. |
|
|
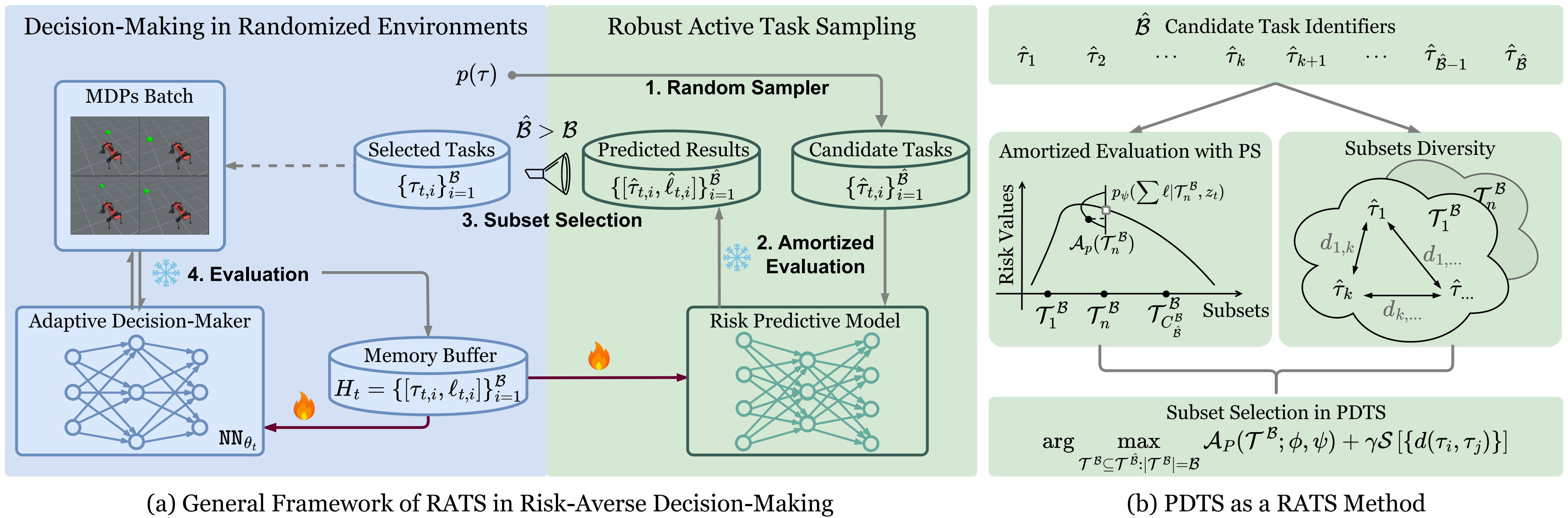
Fast and Robust: Task Sampling with Posterior and Diversity Synergies for Adaptive Decision-Makers in Randomized Environments
Yun Qu*, Qi (Cheems) Wang*, Yixiu Mao*, Yiqin Lv, Xiangyang Ji ICML, 2025 project page / paper / code We propose an easy-to-implement method, referred to as Posterior and Diversity Synergized Task Sampling (PDTS), to accommodate fast and robust sequential decision-making. |
|
|
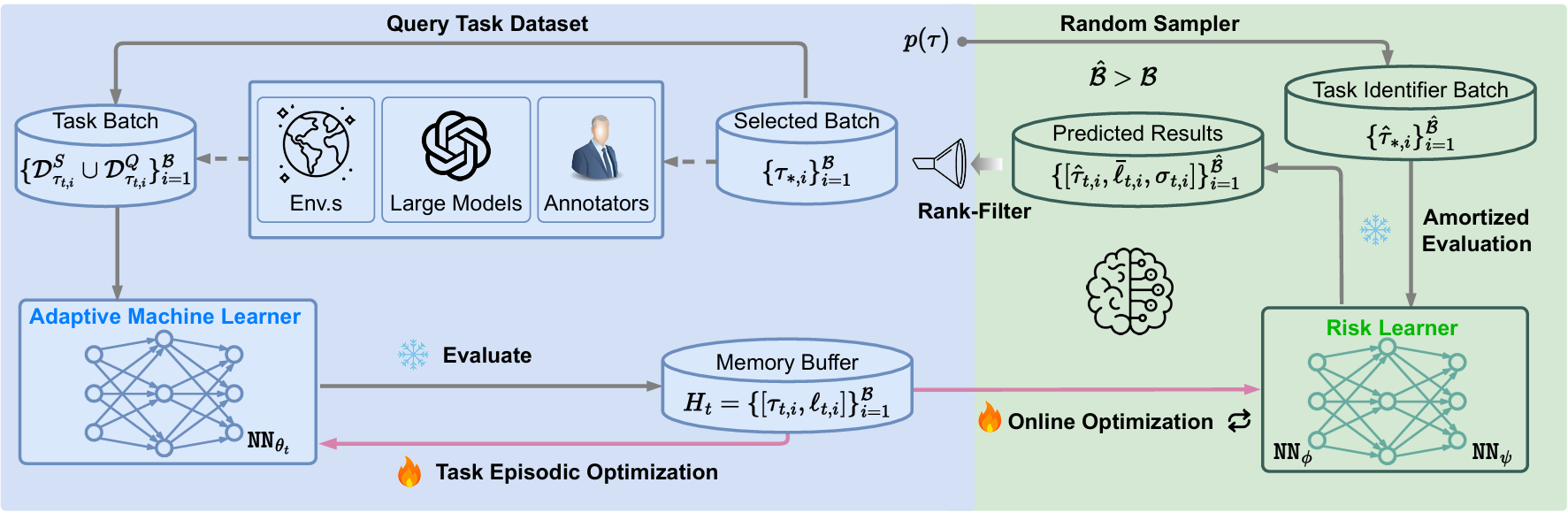
Model Predictive Task Sampling for Efficient and Robust Adaptation
Qi (Cheems) Wang*, Zehao Xiao*, Yixiu Mao*, Yun Qu*, Jiayi Shen, Yiqin Lv, Xiangyang Ji arxiv, 2025 paper / code We introduce Model Predictive Task Sampling (MPTS), a framework that bridges the task space and adaptation risk landscape, providing a theoretical foundation for robust active task sampling. |
|
|
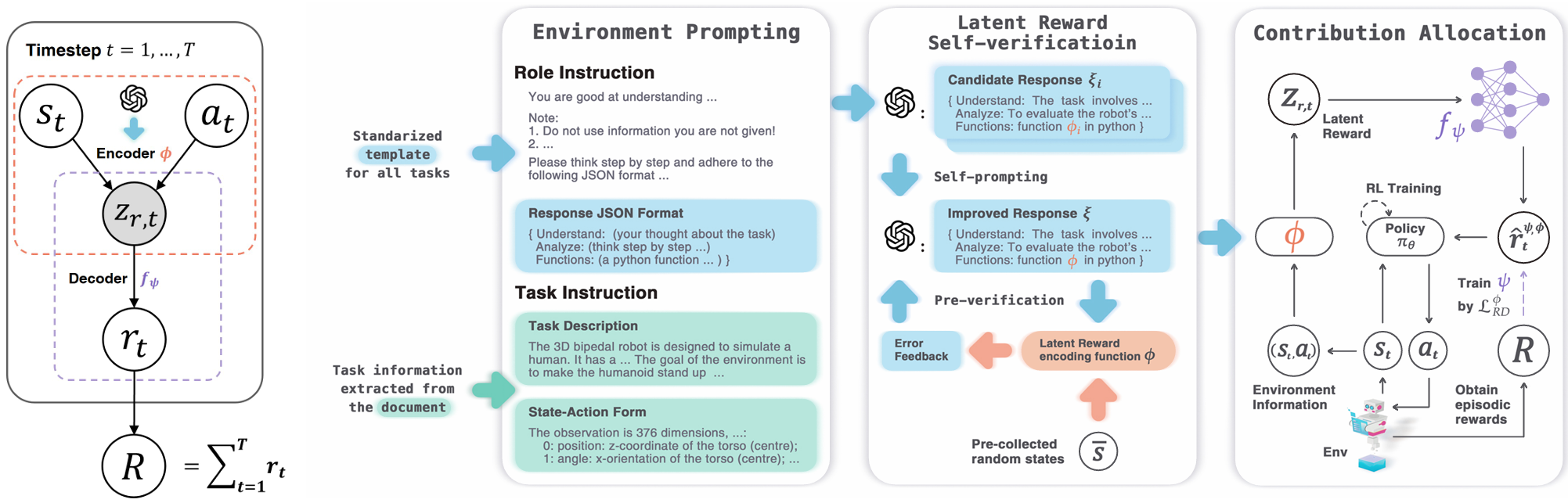
Latent Reward: LLM-Empowered Credit Assignment in Episodic Reinforcement Learning
Yun Qu*, Yuhang Jiang*, Boyuan Wang, Yixiu Mao, Qi (Cheems) Wang*, Chang Liu, Xiangyang Ji AAAI, 2025 paper / code We introduce LaRe, a novel LLM-empowered symbolic-based decision-making framework, to improve credit assignment in episodic reinforcement learning. |
|
|
Doubly Mild Generalization for Offline Reinforcement Learning
Yixiu Mao, Qi (Cheems) Wang, Yun Qu, Yuhang Jiang, Xiangyang Ji NeurIPS, 2024 paper / code To appropriately exploit generalization in offline RL, we propose Doubly Mild Generalization (DMG), comprising (i) mild action generalization and (ii) mild generalization propagation. |
|
|
Offline reinforcement learning with ood state correction and ood action suppression
Yixiu Mao, Qi (Cheems) Wang, Chen Chen, Yun Qu, Xiangyang Ji NeurIPS, 2024 paper / code We propose SCAS, a simple yet effective approach that unifies OOD state correction and OOD action suppression in offline RL. |
|
|
Choices are More Important than Efforts: LLM Enables Efficient Multi-Agent Exploration
Yun Qu, Boyuan Wang, Yuhang Jiang, Jianzhun Shao, Yixiu Mao, Qi (Cheems) Wang*, Chang Liu, Xiangyang Ji arxiv, 2024 paper This paper introduces a systematic approach, termed LEMAE, choosing to channel informative task-relevant guidance from a knowledgeable Large Language Model (LLM) for Efficient Multi-Agent Exploration. |
|
|
Robust Fast Adaptation from Adversarially Explicit Task Distribution Generation
Qi (Cheems) Wang*, Yiqin Lv*, Yixiu Mao*, Yun Qu, Yi Xu, Xiangyang Ji KDD, 2025 project page / paper / code We consider explicitly generative modeling task distributions placed over task identifiers and propose robustifying fast adaptation from adversarial training. |
|
|
LLM-Empowered State Representation for Reinforcement Learning
Boyuan Wang*, Yun Qu*, Yuhang Jiang, Chang Liu, Wenming Yang, Xiangyang Ji ICML, 2024 paper / code We propose LLM-Empowered State Representation (LESR), a novel approach that utilizes LLM to autonomously generate task-related state representation codes which help to enhance the continuity of network mappings and facilitate efficient training. |
|
|
Hokoff: Real Game Dataset from Honor of Kings and its Offline Reinforcement Learning Benchmarks
Yun Qu*, Boyuan Wang*, Jianzhun Shao*, Yuhang Jiang, Chen Chen, Zhenbin Ye, Linc Liu, Yang Feng, Lin Lai, Hongyang Qin, Minwen Deng, Juchao Zhuo, Deheng Ye, Qiang Fu, Yang Guang, Wei Yang, Lanxiao Huang, Xiangyang Ji NeurIPS D&B Track, 2023 project page / paper / code We propose Hokoff, a comprehensive set of pre-collected datasets that covers both offline RL and offline MARL, accompanied by a robust framework, to facilitate further research. |
|
|
Counterfactual Conservative Q Learning for Offline Multi-Agent Reinforcement Learning
Jianzhun Shao*, Yun Qu*, Chen Chen, Hongchang Zhang, Xiangyang Ji NeurIPS, 2023 paper / code We propose a novel multi-agent offline RL algorithm, named CounterFactual Conservative Q-Learning (CFCQL) to conduct conservative value estimation. |
|
|
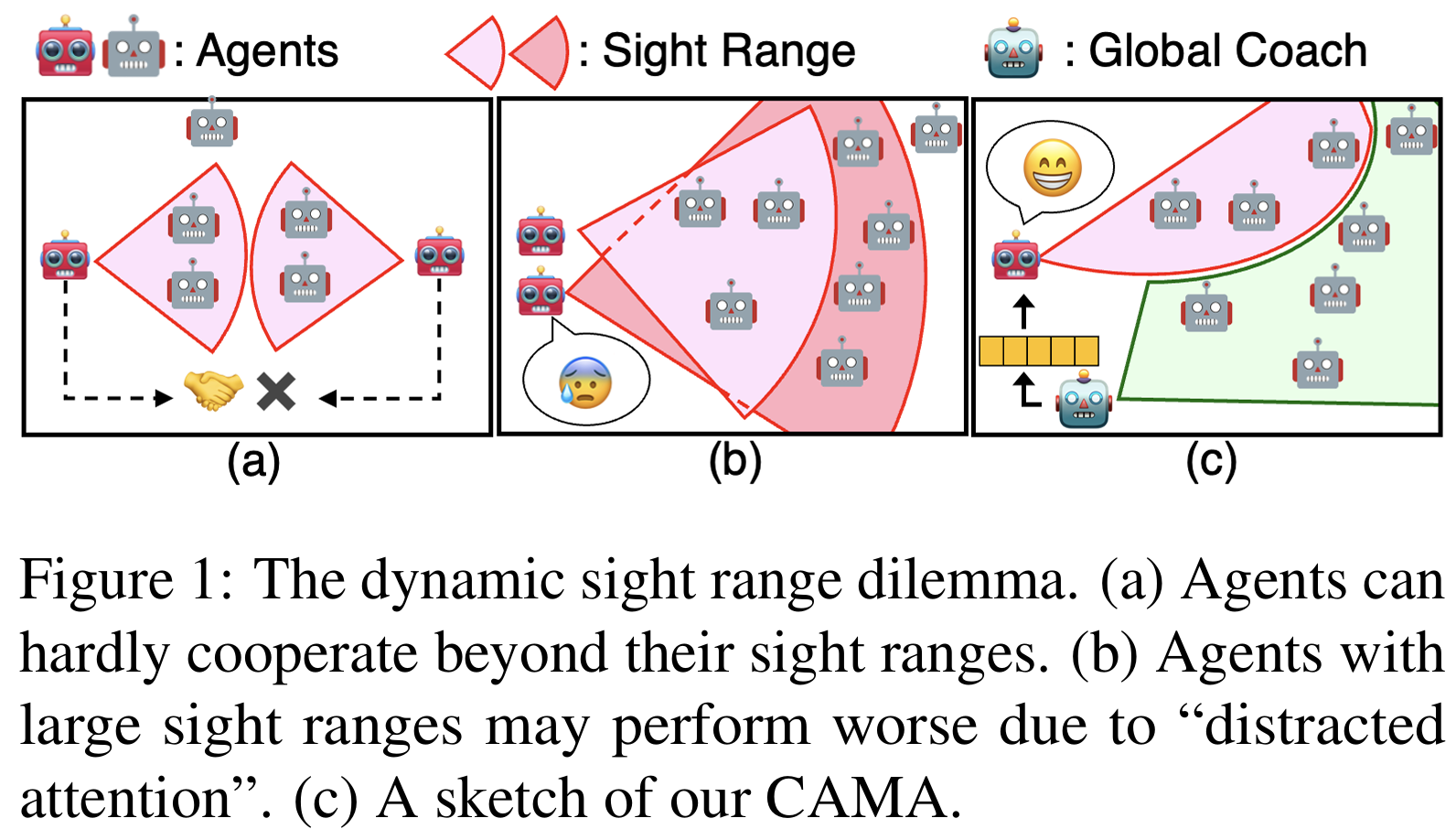
Complementary Attention for Multi-Agent Reinforcement Learning
Jianzhun Shao, Hongchang Zhang, Yun Qu, Chang Liu, Shuncheng He, Yuhang Jiang, Xiangyang Ji ICML, 2023 paper / code In this paper, we propose Complementary Attention for Multi-Agent reinforcement learning (CAMA), which applies a divide-and-conquer strategy on input entities accompanied with the complementary attention of enhancement and replenishment. |



MiscellaneousAcademic Service
Awards & Honors
CollaborationsI'm fortunate to collaborate with researchers from THU-IDM and other institutions. |
|
Website template from Jon Barron |