|
Yun Qu | 曲云 I'm a fourth-year Ph.D. student (Since 2022) in the Department of Automation at Tsinghua University, advised by Prof. Xiangyang Ji. My research focuses on Reinforcement Learning and Large Language Models. I work with the THU-IDM team, where we develop efficient algorithms for decision-making. Prior to my doctoral studies, I received my B.E. degree from the Department of Automation at Tsinghua University in 2022. |

|
News
|
Research (22 publications)I'm interested in Reinforcement Learning and Large Language Models. My research focuses on efficient and intelligent decision-making with minimal environment interactions. |
|
▶
2026(9 papers) |
|
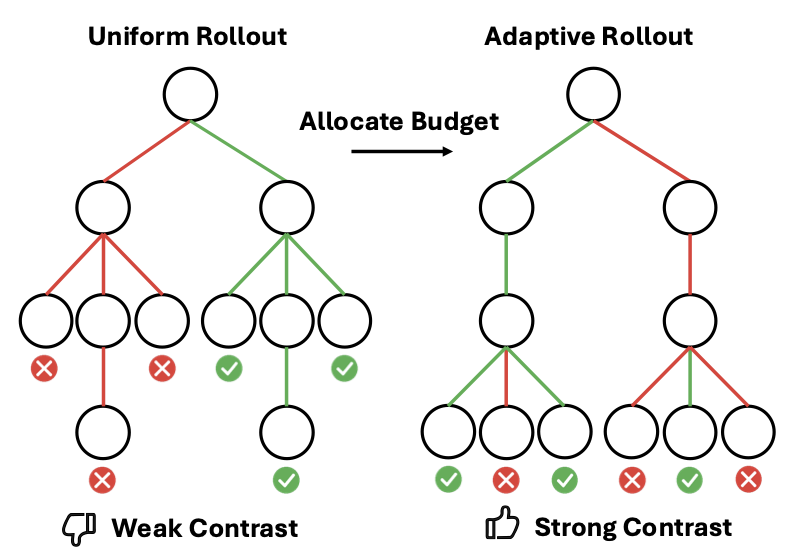
TRACE: A Unified Rollout Budget Allocation Framework for Efficient Agentic Reinforcement Learning
Heming Zou, Qi (Cheems) Wang, Yun Qu, Yuhang Jiang, Lizhou Cai, Ru Peng, Xin Xu, Weijie Liu, Kai Yang, Saiyong Yang, Xiangyang Ji arxiv, 2026 paper We introduce Tree Rollout Allocation for Contrastive Exploration (TRACE), a unified rollout allocation framework that enhances reward contrast within a fixed sampling budget. |
|
|
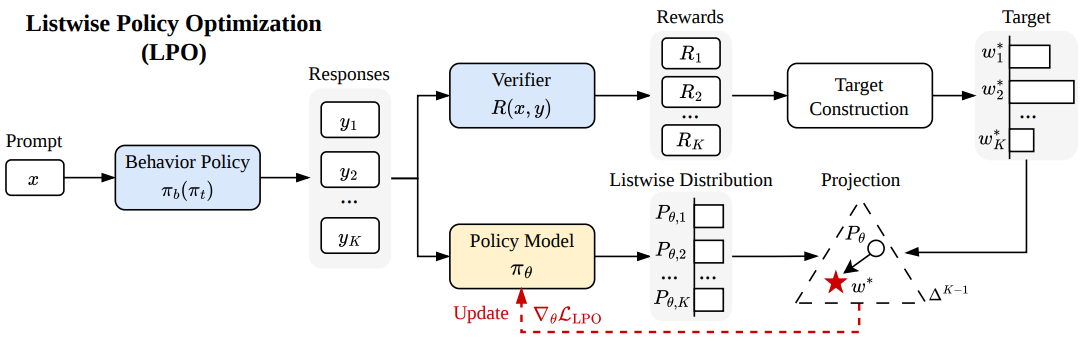
Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
Yun Qu, Qi (Cheems) Wang, Yixiu Mao, Heming Zou, Yuhang Jiang, Yingyue Li, Wutong Xu, Lizhou Cai, Weijie Liu, Clive Bai, Kai Yang, Yangkun Chen, Saiyong Yang, Xiangyang Ji arxiv, 2026 paper This work reveals that group-based RLVR methods share a common geometric structure: each implicitly defines a target distribution on the response simplex and projects toward it via first-order approximation. Building on this insight, we propose Listwise Policy Optimization (LPO) to explicitly conduct the target-projection, which demystifies the implicit target by restricting the proximal RL objective to the response simplex, and then projects the policy via exact divergence minimization. |
|
|
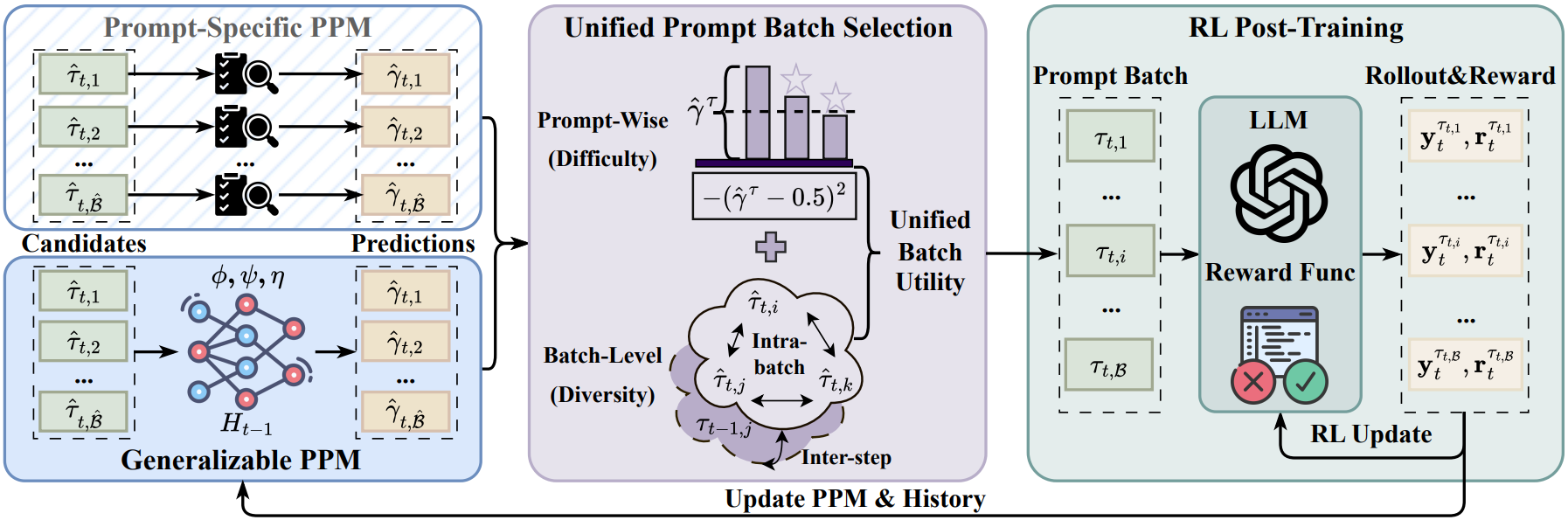
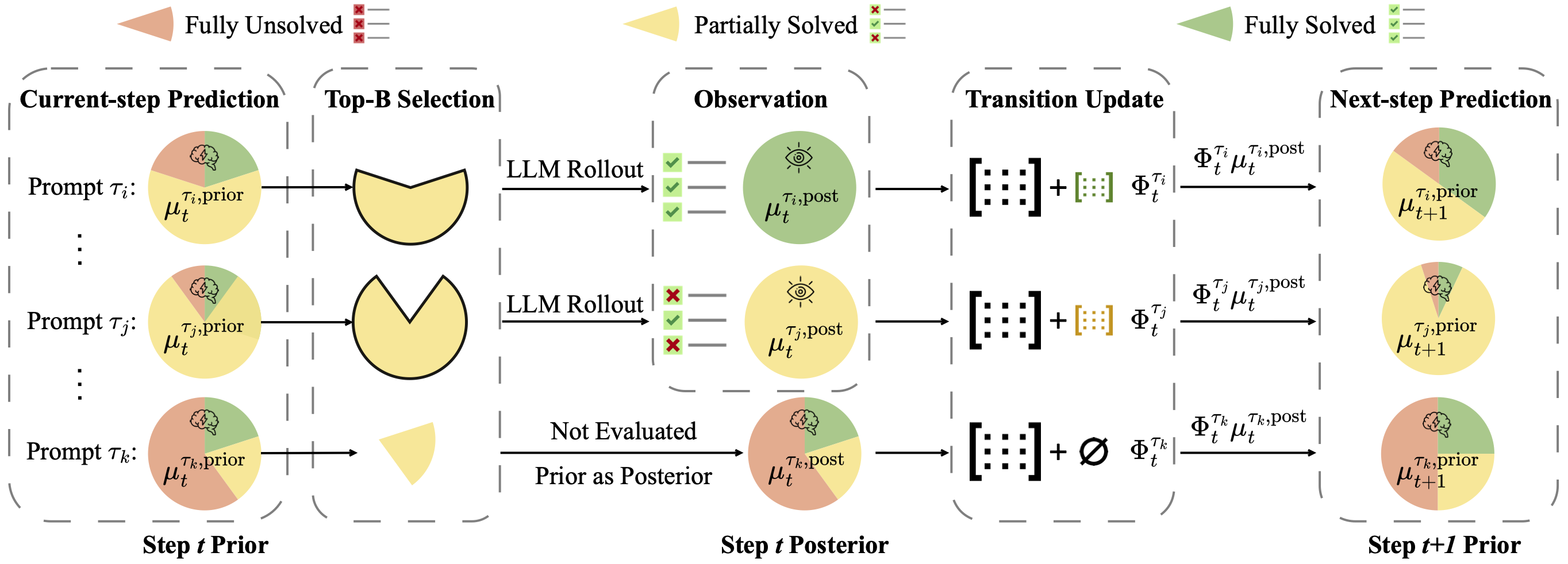
Small Generalizable Prompt Predictive Models Can Steer Efficient RL Post-Training of Large Reasoning Models
Yun Qu, Qi (Cheems) Wang, Yixiu Mao, Heming Zou, Yuhang Jiang, Weijie Liu, Clive Bai, Kai Yang, Yangkun Chen, Saiyong Yang, Xiangyang Ji ICML, 2026 paper / code This study introduces Generalizable Predictive Prompt Selection (GPS), which performs Bayesian inference towards prompt difficulty using a lightweight generative model trained on the shared optimization history. |
|
|
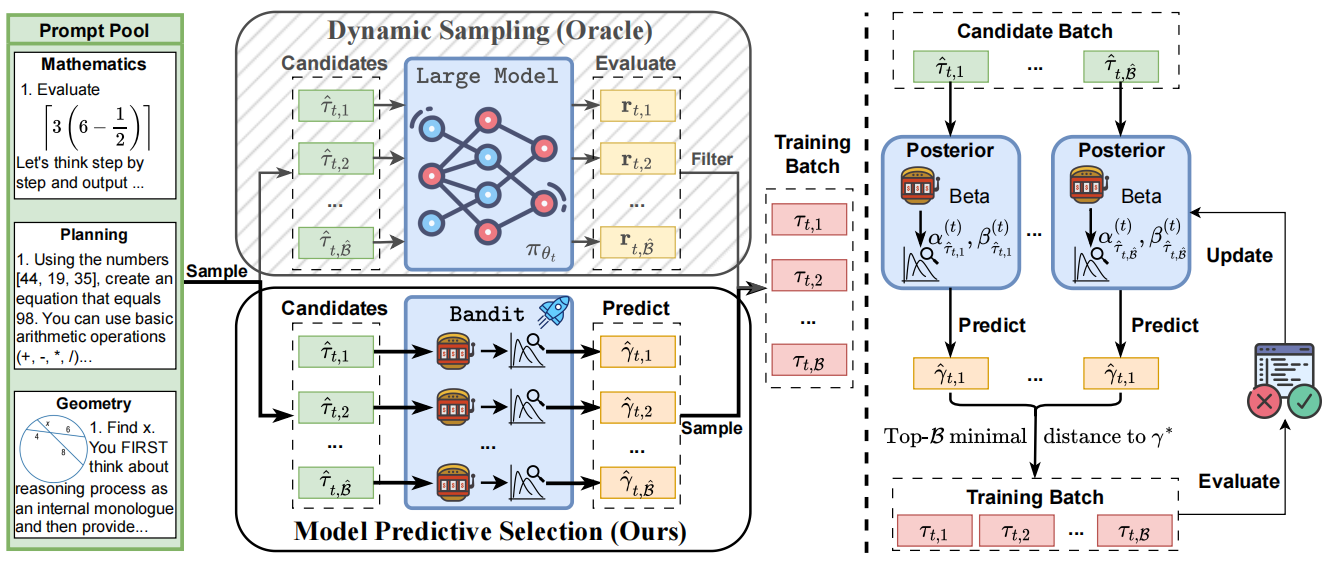
Can Prompt Difficulty be Online Predicted for Accelerating RL Finetuning of Reasoning Models?
Yun Qu, Qi (Cheems) Wang, Yixiu Mao, Vincent Tao Hu, Björn Ommer, Xiangyang Ji KDD, 2026 paper / code This work introduces Model Predictive Prompt Selection, a Bayesian risk-predictive framework that online estimates prompt difficulty without requiring costly LLM interactions. |
|
|
Dynamics-Predictive Sampling for Active RL Finetuning of Large Reasoning Models
Yixiu Mao, Yun Qu, Qi (Cheems) Wang, Heming Zou, Xiangyang Ji ICLR, 2026 paper / code This work proposes Dynamics Predictive Sampling (DPS), which online predicts and selects informative prompts by inferring their learning dynamics prior to costly rollouts. |
|
|
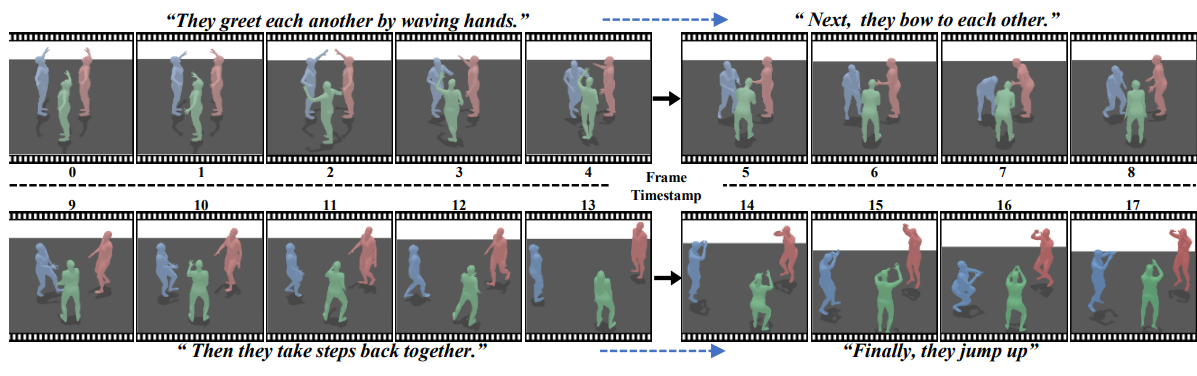
HINT: Hierarchical Interaction Modeling for Autoregressive Multi-Human Motion Generation
Mengge Liu, Yan Di, Gu Wang, Yun Qu, Dekai Zhu, Yanyan Li, Xiangyang Ji arXiv, 2026 paper We introduce HINT, the first autoregressive framework for multi-human motion generation with hierarchical interaction modeling in diffusion. HINT leverages disentangled motion representation and a sliding-window strategy, achieving an FID of 3.100 on InterHuman, significantly improving over the previous state-of-the-art. |
|
|
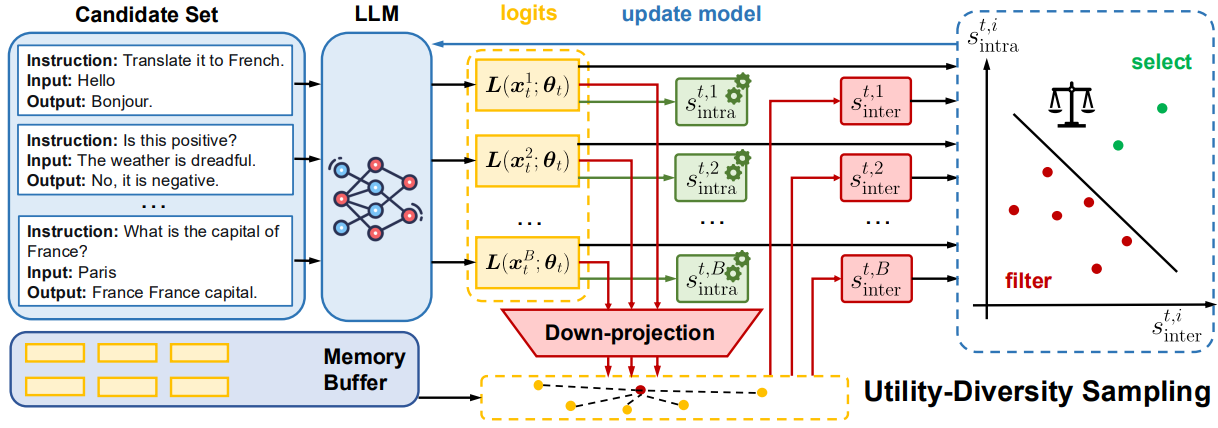
Utility-Diversity Aware Online Batch Selection for LLM Supervised Fine-tuning
Heming Zou, Yixiu Mao, Yun Qu, Qi (Cheems) Wang, Xiangyang Ji ICML, 2026 paper / code We develop UDS (Utility-Diversity Sampling), a framework for efficient online batch selection in LLM supervised fine-tuning that leverages the nuclear norm of the logits matrix to capture both data utility and intra-sample diversity, eliminating the need for external resources. |
|
|
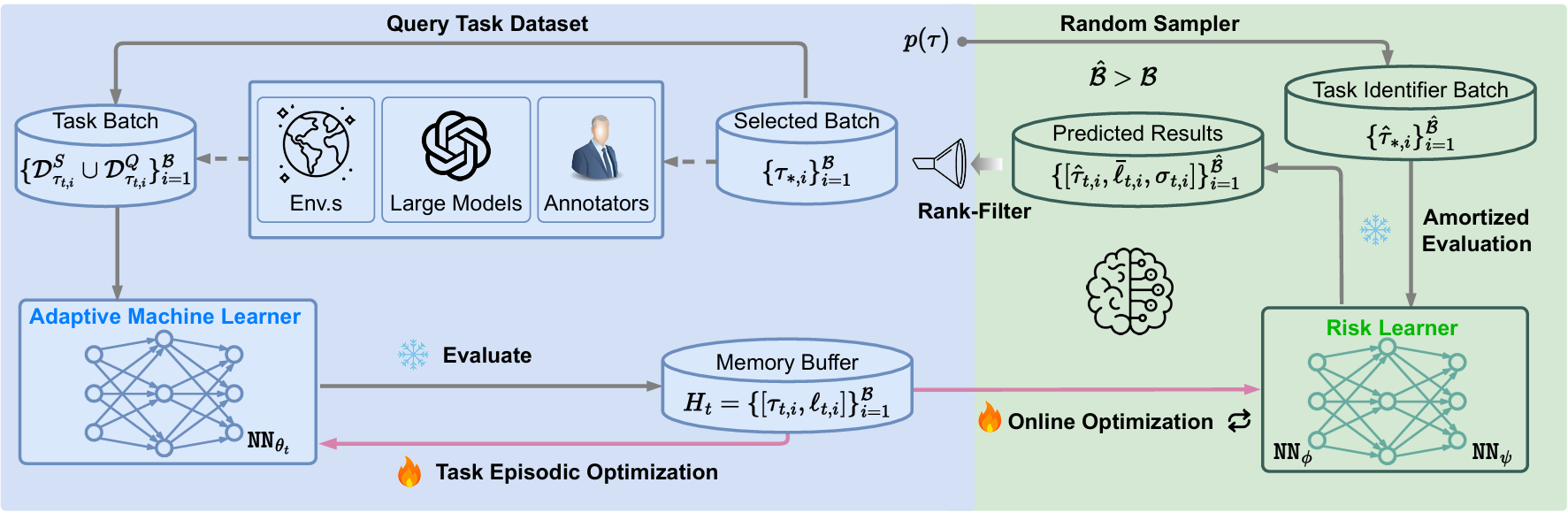
Model Predictive Task Sampling for Efficient and Robust Adaptation
Qi (Cheems) Wang*, Zehao Xiao*, Yixiu Mao*, Yun Qu*, Jiayi Shen, Yiqin Lv, Xiangyang Ji Nature Communications, 2026 paper / code We introduce Model Predictive Task Sampling (MPTS), a framework that bridges the task space and adaptation risk landscape, providing a theoretical foundation for robust active task sampling. |
|
|
Stop Wandering, Find the Keys: LLMs Discriminate Key States for Efficient Multi-Agent Exploration
Yun Qu, Boyuan Wang, Yuhang Jiang, Jianzhun Shao, Yixiu Mao, Heming Zou, Chang Liu, Qi (Cheems) Wang, Meiqin Liu, Xiangyang Ji Science China Information Sciences (CCF A, IF 7.6), 2026 paper This paper introduces a systematic approach, termed LEMAE, choosing to channel informative task-relevant guidance from a knowledgeable Large Language Model (LLM) for Efficient Multi-Agent Exploration. |

|
▶
2025(6 papers) |
|
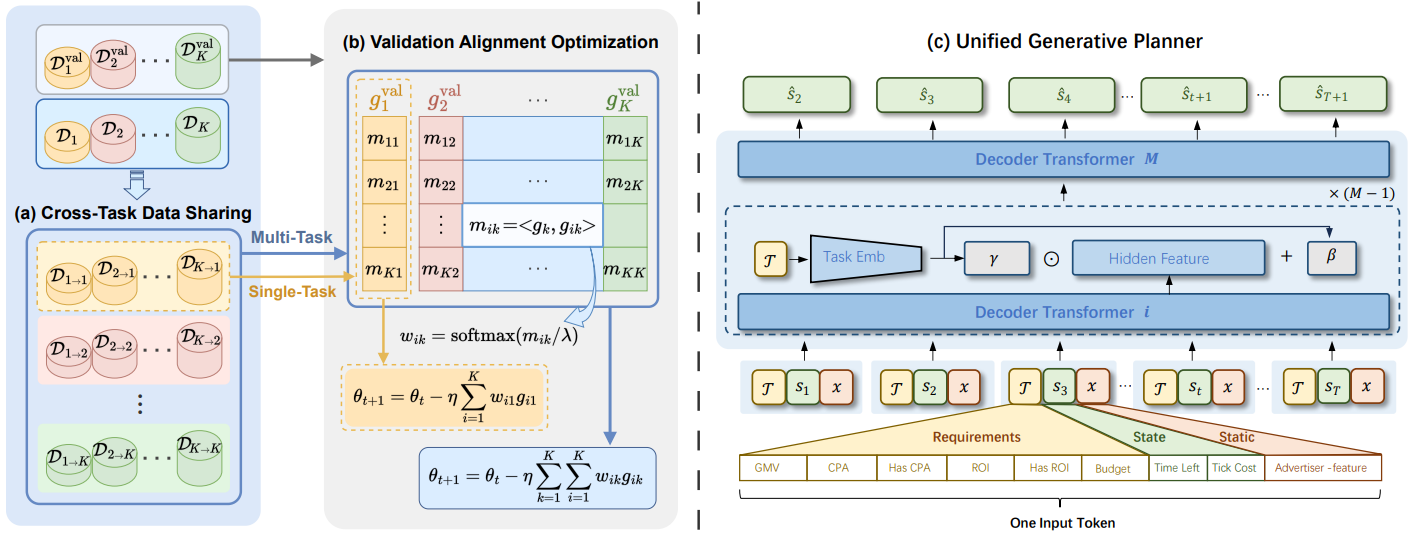
VAO: Validation-Aligned Optimization for Cross-Task Generative Auto-Bidding
Yiqin Lv*, Zhiyu Mou*, Miao Xu, Jinghao Chen, Qi (Cheems) Wang, Yixiu Mao, Yun Qu, Rongquan Bai, Chuan Yu, Jian Xu, Bo Zheng, Xiangyang Ji arXiv, 2025 paper We present Validation-Aligned Optimization (VAO), a principled data-sharing method that adaptively reweights cross-task data contributions based on validation performance feedback. |
|
|
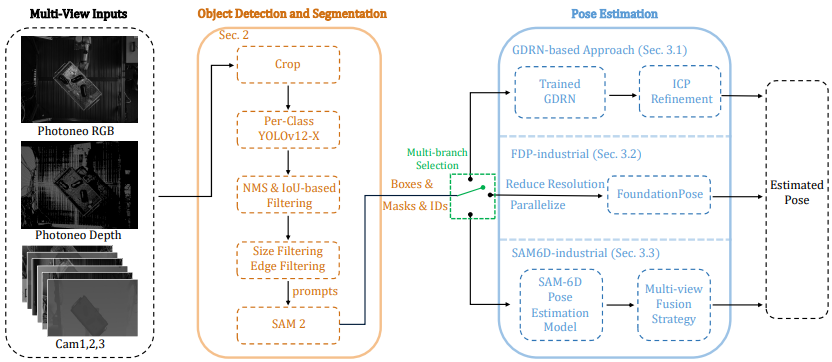
Lessons and Winning Solutions in Industrial Object Detection and Pose Estimation from the 2025 Bin-Picking Perception Challenge
Ziqin Huang*, Chengxi Li*, Yingyue Li*, Xingyu Liu*, Chenyangguang Zhang, Ruida Zhang, Bowen Fu, Xinggang Hu, Yun Qu, Mengge Liu, Yixiu Mao, Wendong Huang, Gu Wang, Xiangyang Ji ICCV R6D Workshop, 2025 Grand Prize Winner paper This paper analyzes challenges in object pose estimation within industrial environments, based on our winning solutions in the 2025 Perception Challenge for Bin-Picking. We highlight two unexpected observations: methods trained on object-specific datasets performed worse than those on unseen data, and evaluation results varied significantly depending on the chosen metrics. |
|
|
Adaptive Neighborhood-Constrained Q Learning for Offline Reinforcement Learning
Yixiu Mao, Yun Qu, Qi (Cheems) Wang*, Xiangyang Ji NeurIPS, 2025 Spotlight paper / code This work aims to address the over-conservatism of the density and sample constraints while avoiding complex behavior modeling required by the support constraint. |
|
|
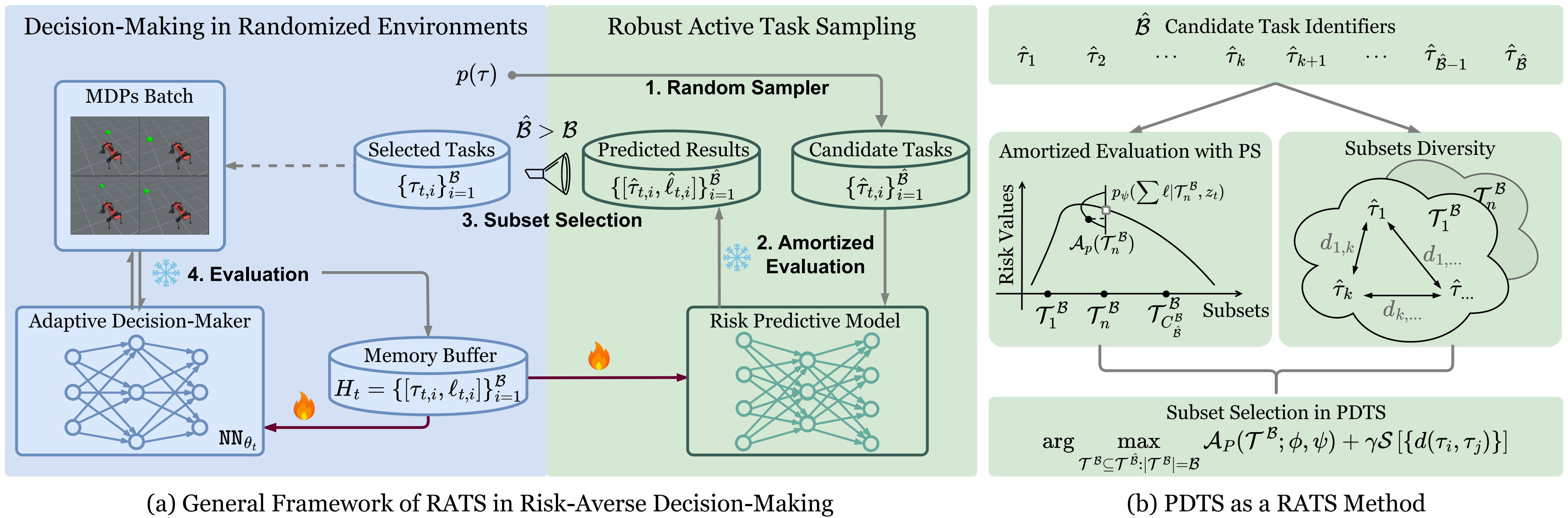
Fast and Robust: Task Sampling with Posterior and Diversity Synergies for Adaptive Decision-Makers in Randomized Environments
Yun Qu*, Qi (Cheems) Wang*, Yixiu Mao*, Yiqin Lv, Xiangyang Ji ICML, 2025 project page / paper / code We propose an easy-to-implement method, referred to as Posterior and Diversity Synergized Task Sampling (PDTS), to accommodate fast and robust sequential decision-making. |
|
|
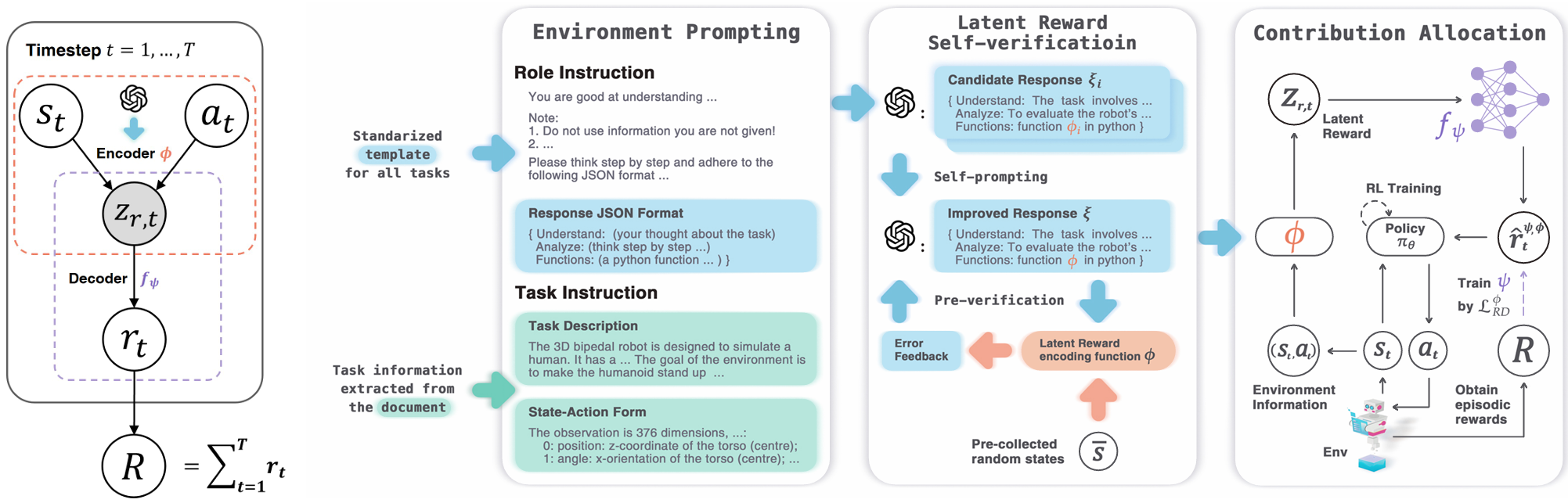
Latent Reward: LLM-Empowered Credit Assignment in Episodic Reinforcement Learning
Yun Qu*, Yuhang Jiang*, Boyuan Wang, Yixiu Mao, Qi (Cheems) Wang*, Chang Liu, Xiangyang Ji AAAI, 2025 paper / code We introduce LaRe, a novel LLM-empowered symbolic-based decision-making framework, to improve credit assignment in episodic reinforcement learning. |
|
|
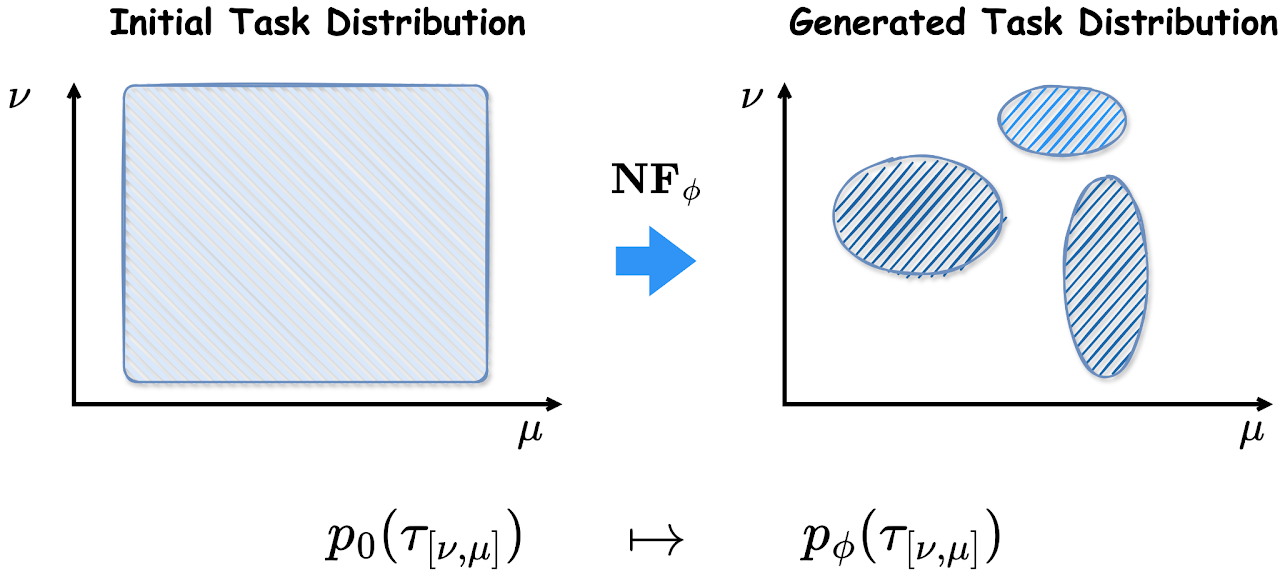
Robust Fast Adaptation from Adversarially Explicit Task Distribution Generation
Qi (Cheems) Wang*, Yiqin Lv*, Yixiu Mao*, Yun Qu, Yi Xu, Xiangyang Ji KDD, 2025 project page / paper / code We consider explicitly generative modeling task distributions placed over task identifiers and propose robustifying fast adaptation from adversarial training. |

|
▶
2024(3 papers) |
|
Doubly Mild Generalization for Offline Reinforcement Learning
Yixiu Mao, Qi (Cheems) Wang, Yun Qu, Yuhang Jiang, Xiangyang Ji NeurIPS, 2024 paper / code To appropriately exploit generalization in offline RL, we propose Doubly Mild Generalization (DMG), comprising (i) mild action generalization and (ii) mild generalization propagation. |
|
|
Offline reinforcement learning with ood state correction and ood action suppression
Yixiu Mao, Qi (Cheems) Wang, Chen Chen, Yun Qu, Xiangyang Ji NeurIPS, 2024 paper / code We propose SCAS, a simple yet effective approach that unifies OOD state correction and OOD action suppression in offline RL. |
|
|
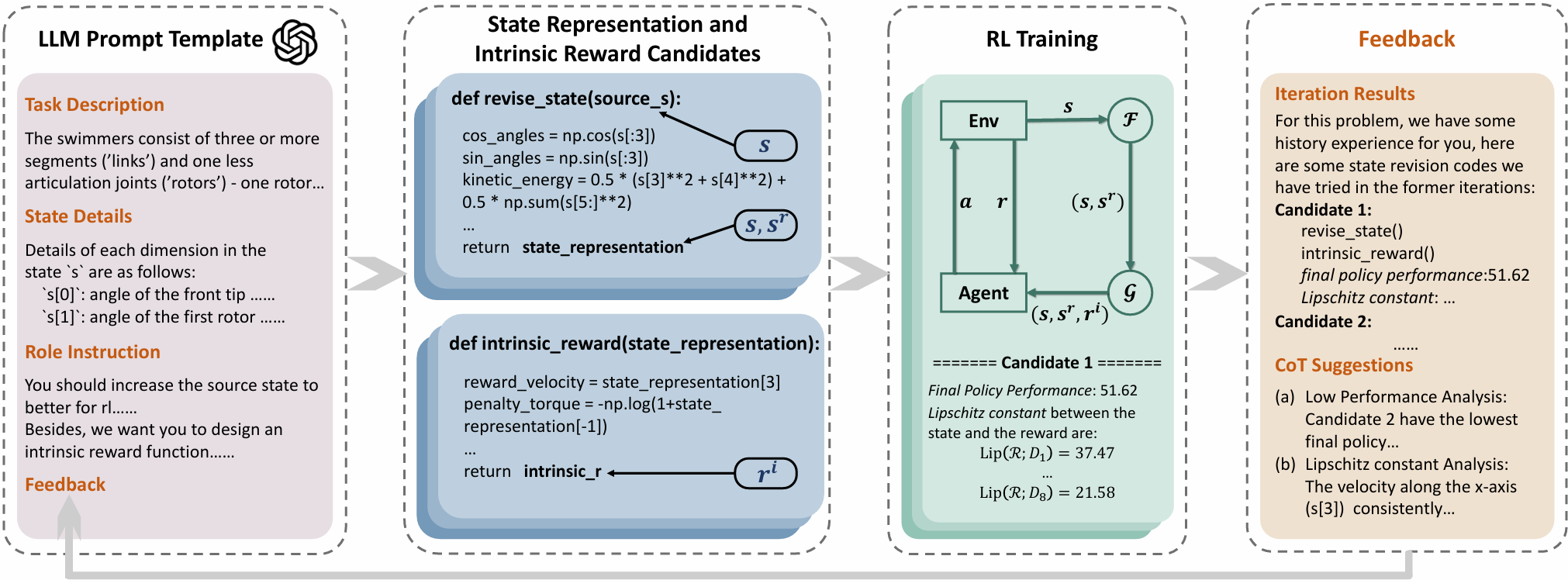
LLM-Empowered State Representation for Reinforcement Learning
Boyuan Wang*, Yun Qu*, Yuhang Jiang, Chang Liu, Wenming Yang, Xiangyang Ji ICML, 2024 paper / code We propose LLM-Empowered State Representation (LESR), a novel approach that utilizes LLM to autonomously generate task-related state representation codes which help to enhance the continuity of network mappings and facilitate efficient training. |

|
▶
2023(4 papers) |
|
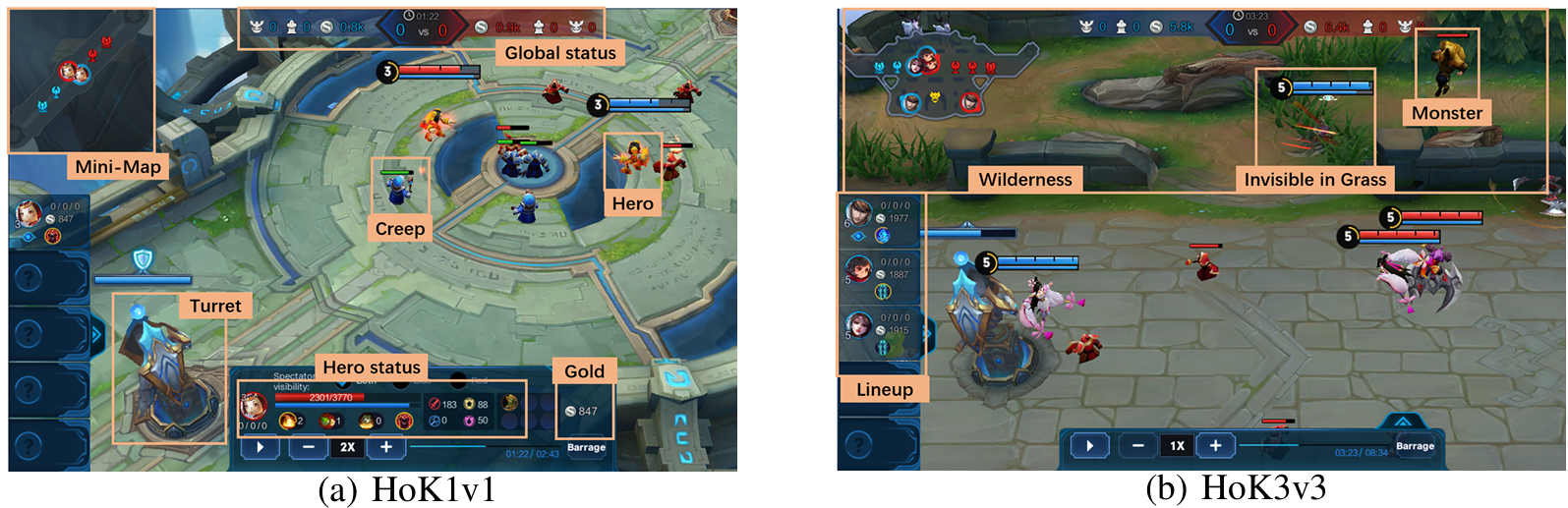
Hokoff: Real Game Dataset from Honor of Kings and its Offline Reinforcement Learning Benchmarks
Yun Qu*, Boyuan Wang*, Jianzhun Shao*, Yuhang Jiang, Chen Chen, Zhenbin Ye, Linc Liu, Yang Feng, Lin Lai, Hongyang Qin, Minwen Deng, Juchao Zhuo, Deheng Ye, Qiang Fu, Yang Guang, Wei Yang, Lanxiao Huang, Xiangyang Ji NeurIPS D&B Track, 2023 project page / paper / code We propose Hokoff, a comprehensive set of pre-collected datasets that covers both offline RL and offline MARL, accompanied by a robust framework, to facilitate further research. |
|
|
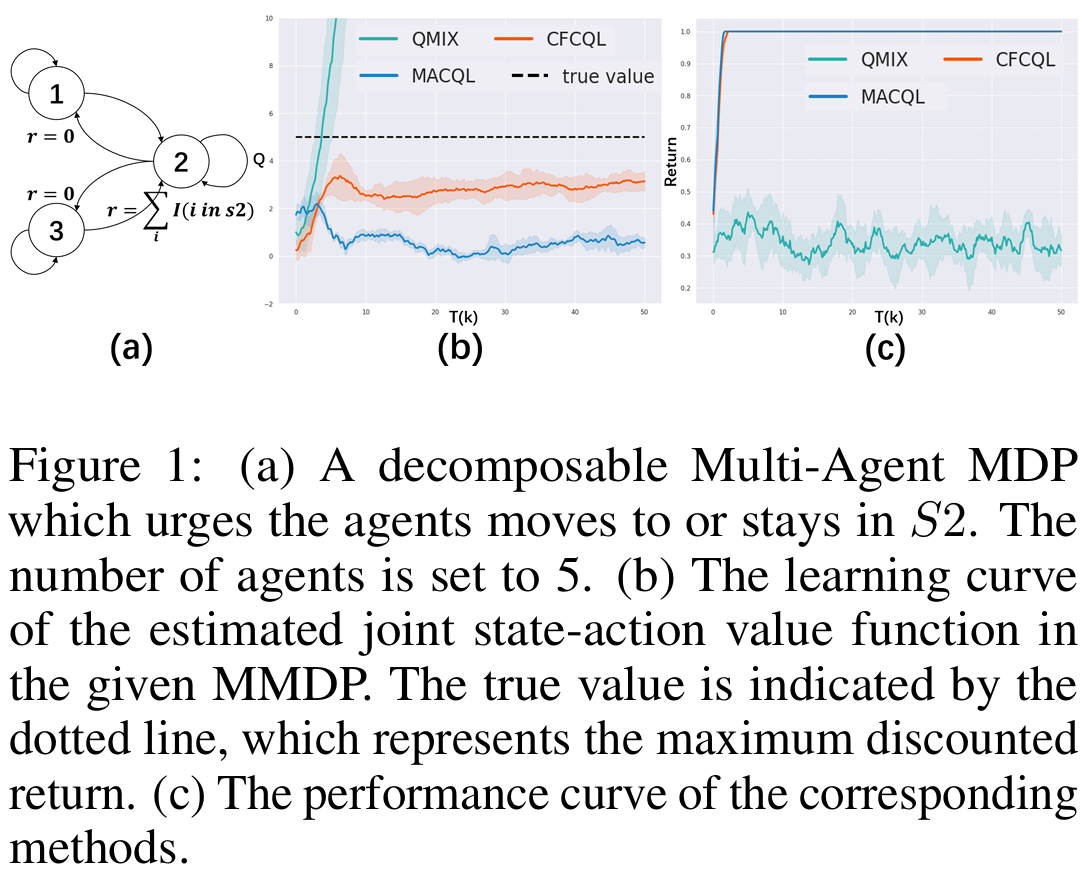
Counterfactual Conservative Q Learning for Offline Multi-Agent Reinforcement Learning
Jianzhun Shao*, Yun Qu*, Chen Chen, Hongchang Zhang, Xiangyang Ji NeurIPS, 2023 paper / code We propose a novel multi-agent offline RL algorithm, named CounterFactual Conservative Q-Learning (CFCQL) to conduct conservative value estimation. |
|
|
Complementary Attention for Multi-Agent Reinforcement Learning
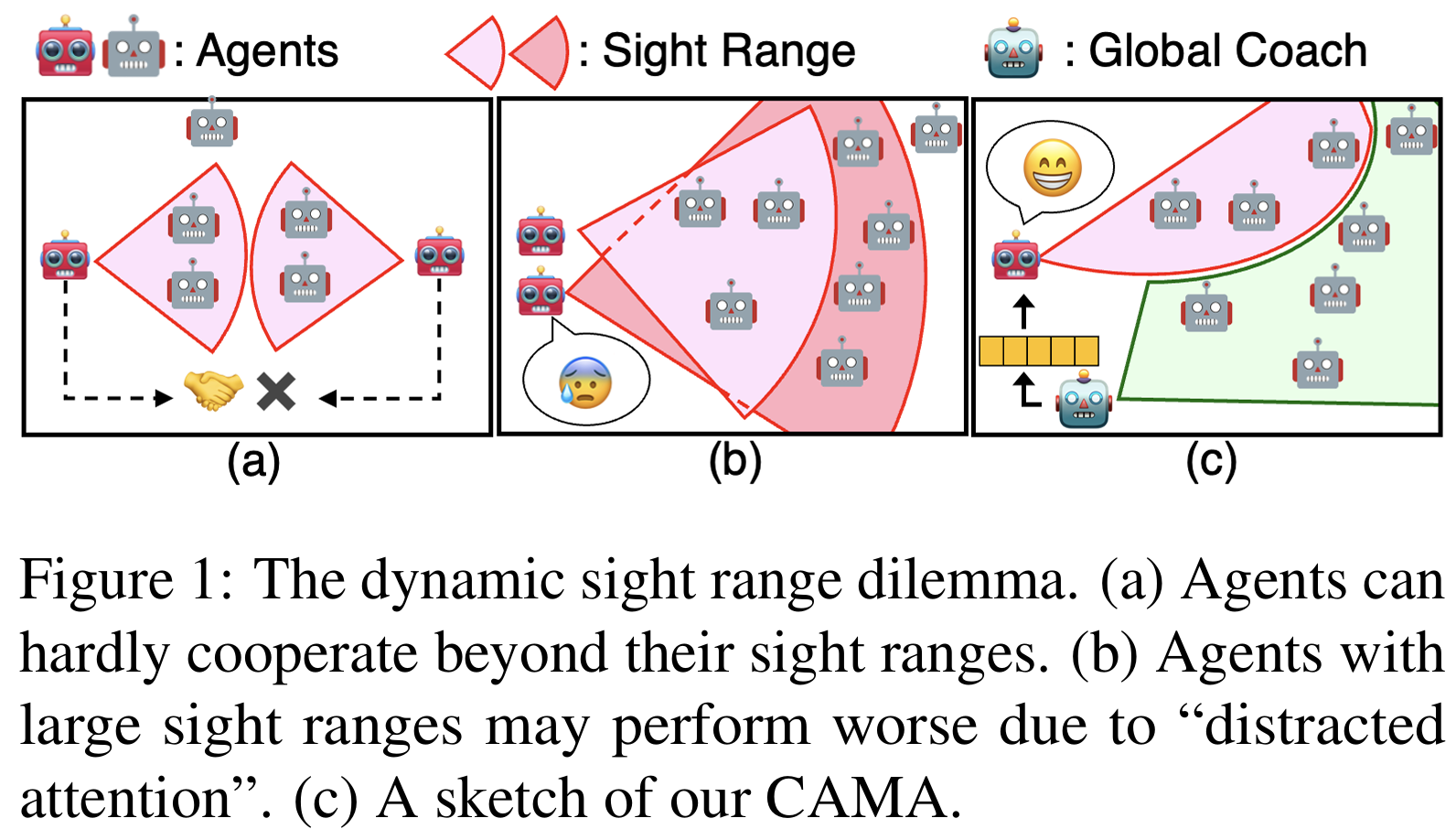
Jianzhun Shao, Hongchang Zhang, Yun Qu, Chang Liu, Shuncheng He, Yuhang Jiang, Xiangyang Ji ICML, 2023 paper / code In this paper, we propose Complementary Attention for Multi-Agent reinforcement learning (CAMA), which applies a divide-and-conquer strategy on input entities accompanied with the complementary attention of enhancement and replenishment. |
|
|
HoK3v3: an Environment for Generalization in Heterogeneous Multi-agent Reinforcement Learning
Lin Liu, Jianzhun Shao, Xinkai Chen, Yun Qu, Boyuan Wang, Zhenbin Ye, Yuexuan Tu, Hongyang Qin, Yang Jun Feng, Lin Lai, Yuanqin Wang, Meng Meng, Wenjun Wang, Xiyang Ji, Qiang Fu, Lanxiao Huang, Minwen Deng, Yang Wei, Houqiang Li, Wengang Zhou, Ning Xie, Xiangyang Ji, Lvfang Tao, Lin Yuan, Juchao Zhuo, Yang Guang, Deheng Ye arxiv, 2023 paper / code We introduce HoK3v3, a 3v3 game environment based on Honor of Kings for multi-agent reinforcement learning research, posing a unique challenge for generalization in heterogeneous MARL with diverse heroes and lineups. |
Internships
|
MiscellaneousAcademic Service
Awards & Honors
CollaborationsI'm fortunate to collaborate with researchers from THU-IDM and other institutions. |
|
Website template from Jon Barron |